{kind=link}

All credit for the source and/or referenced material goes to the named author(s).
Ryan reffers to Lazy Loading as Progressive Hydration, but it seems that, as per Qwik’s Misko Hevery’s definition, it would be more befitting to apply that name to a sort of “Out of Order+”? Misko call that “Resumability” and considers that it doesn’t fit the definition of Hydration at all.
| Hydration Type | Examples 1 |
|---|---|
| Static Routes (No Hydration) | Remix, SvelteKit, SolidStart |
| Lazy Hydration | Astro |
| Serializing Data in HTML | Prism Compiler |
| Islands (Partial Hydration) | Marko, Astro |
| Out of Order Hydration | Qwik |
| Server Components | React Server Components |
In the context of JavaScript frontend frameworks - Hydration is the process of initializing a page client-side after its been SSR’d and delivered.
It is, in most current frameworks, a costly process that leaves an noninteractive page on the client until completed.
While SSR does make your content visible faster, more often than not it ends up pushing back Time to Interactive (TTI) and causing the bundle to grow larger, as you still will need to ship the whole framework and components’ code for client-side hydration alongside the SSR’d version.
Client-side hydration presents two main downsides; current frameworks make it so that the full process of rendering is required to hydrate what was SSR’d and sent down, and the fact that we end up sending everything across twice, once as HTML and once as JavaScript.
It generally gets sent across in 3 forms:
The template exists in both the rendered form and the bundled JS, and the data also exist as part of the rendered HTML and in some form - usually a script tag - rendered into the HTML.
What does it mean that the data is part of a script tag in the HTML? Wouldn’t it be fetched asynchronously as the components are rendered? Is this some standard optimisation when doing SSR?
With CSR, we just send down the template and the requested data to render it, without duplication.
Static routes simply means no JavaScript - or at least no framework JavaScript. In theory you could include some plain JS, but this is not desireable if you’re already working with a framework.
Great in some use-cases, but doesn’t solve any of this issues pertaining to app-like SPAs.
This method will eventually load the JavaScript, but it’ll be in response to some stimuli and/or interaction, rather than to send it down by default. This is only beneficial if the user doesn’t ever interact with the page.
Most current frontend frameworks need to hydrate top-down from the root. For an SPA, this means that to hydrate you will need all of the code, and start from the very top to get to hydrating any nested component.
This also presents further downsides in that you’ll probably leave the app hanging to get through all of that work at some random, unexpected, moment for the user, and it also demands that all the data is serialized and sent down.
This technique is a complement to lazy-loading and others and consists in deriving the application state from the data already in the rendered HTML.
Unfortunately, it presents some important limitations and challenges; view and model rarely match 1:1, and if your HTML contains some derived data for presentation purpose - or that was transformed further as a result of a UI action - (money values, date/time, etc.) then it is almost impossible to re-derive from it.
Furthermore, current frameworks’ hydration method is to rerun the app fully, from the top down, once its on the client. In doing so, the app’s default behavior will be to simply call isomorphic data fetching services to refetch the data as it first did server-side, instead of parsing the DOM and sourcing the data from there. This could be circumvented by setting a client-side cache for the data that’s seeded from what’s available in the markup and is opaque to the fetching service.
Here, isomorphic refers to the fact that those services can be called & consummed in the same way from both the server and the client.
Many apps mostly consist of static, noninteractive, HTML with some dynamic components sprinkled around, and this type of hydration aims to capitalize on that fact. Those few interactive components are called islands, and they are the parts that gets gradually hydrated while the rest of the app stays as-is.
In doing so, only the inputs & props for those top-level components need to be serialize since we’re guaranteed that anythign above is static and stateless, and thus can never re-render.
The problem lies with defining the boundaries. The more granular the better, top-level components only is a start but still requires alot of code to be sent down - essentially every single sub-components from this new Island-defined root.
Ideally, you need a compiler with its own DSL that allows setting boundaries at sub-components level so that both the static top-level parts as well as the unneeded child components can be excluded.
Also of note, islands require SSR on each navigation, turning the app into an MPA. This implies a loss of client-side transitions and loss of client state on navigation. Partial Hydration is in essence an improvement over [[#Static Routes No Hydration|Static Routes]] that allows you to only pay for what you use.
Unclear on loss of client state on navigation. Can’t the state be somehow serialized/cached to browser storage, the History API, or even through the URL itself and passed back down?
Out of Order Hydration is an improvement over Lazy Loading, in the same way Partial Hydration is an upgrade over Static Routes. It aims at breaking the top-down requirements that current frameworks impose, allowing to hydrate a child/sub-component in complete isolation.
This means that a component must, in itself, have everything that’s needed for it to be rendered and hydrated. One possible approach is to use dependency injection to provide inputs and props directly to the component regardless of its lexical context. This still leaves one problem - the fact that child components are normally evaluated lazily, which is the case for almost all modern frameworks.
This, in turn, imposes restrictions over parent-child interactions and impacts the way it needs to be developed and implemented. Furthermore, just like Lazy Loading, it doesn’t avoid data duplication since while it can hydrate granularly, it doesn’t know which components need to be sent to the browser.
#react #react-server-components
Much like Partial Hydration, but that re-renders the static parts on the server, top-down from the app’s root. RSC’s definitions are not sent down to the client, they are SSR’d to a custom format and then sent down in their rendered form to be interepreted by the frontend runtime.
The augmented frontend runtime is able to diff server components trees with the rendered HTML, and conserve client state. You still render to plain HTML for initial render, prior to the runtime being downloaded, or lose the benefits of SSR.
Unclear about whether the runtime diffs the RSC’s custom format with rendered HTML, or with the previous render’s custom format that’s kept in-memory within the runtime …
The custom format is React Fibet Nodes, it probably works just the same as any other React elements under Fiber.
All of these various steps have a high impact on framework-level complexity, in terms of bundling & compiling, as well as on the runtime itself to handle combining Server and Client components through multiple re-renders, keep client state, etc.; but from a developer’s perspective, it enables the best of many options with relatively minimal impact on implementation style and paradigms to consider.
The significant implied complexity cost might not be worth it on smaller & simpler implementations, but very well might be the way to go for larger, more complex applications.
There is currently an implied tradeoff in implementation between Good, Cheap, and Fast, and you’re usually stuck picking two out of the three.
The main determinants here are closely related to the state management strategy chosen between the possible options, namely:
It’s not even clear to me what the mechanics would be here to prevent the rerendering should children props change - even for the exact same value - when working with Hooks , with the implied loss of shouldComponentUpdate() and PureComponent. I believe that you’re essentially required to write/leverage an abstraction that handles state and that prevents updating the children’s props on equal value?
Facebook solved this issue through the use of GraphQL Fragments , which are localized at the component-level, and Relay which composes the fragments and then orchestrates data fetching, caching, etc. at the app level - but this isn’t a silver nullet. This is a heavy solutions that has significant implications on the implementation, namely that any app then requires a GraphQL backend …
The proposed alternative is to now move the components to the server. Since the true problem of the fetching cascade is the latency on the client’s side, fetching and rendering on the server solves most of this issue without much additional tooling.
With RSC, server components and their external dependencies are fully excluded - hence the zero-bundle-size claim - from the frontend bundle, but they currently cannot have any interactivity - that means no state (which excludes most Hooks) or event listeners.
The way to add interactivity is to import client components within a server component and leave these specific parts for the client to handle. One important thing to keep in mind is that a server component can only provide props to a client component that are serializable over the network; meaning that if we’re serializing to JSON, we can only pass down values that are serializable to JSON (see [[#Non-Serializable Data Problem|Qwik’s Explanation of Non-Serializable Data Types]]).
Important to note here that JSX is indeed serializable. This then means that server components can pass JSX as props to client components, and will even process and render the JSX before passing it down - provided that the JSX is itself noninteractive or a Server Component.
<SomeServerComponent.server>
<SomeClientComponent.client>
{/* SSR'd before passing down as "children" prop to client component */}
<SomeServerChildComponent.server />
<p>Some more static JSX</p>
<p>{someServerSideProp}</p>
</SomeClientComponent.client>
</SomeServerComponent.server>Excellent high-level breakdown of Client, Server, and Shared Components features by Shopify
Upon re-rendering - triggered by some interaction from a Client Component - the server component’s full tree will be fetched from the server and SSR’d back from the root of the application. The app can at that point be provided with additional client-context-specific props to be leveraged during rendering of the tree.
Is the only mechanism to pass values to the app through the URL, and will that force you to do from-the-top prop drilling ?
Looks like there might be something on the way in terms of Server Components’ Context
Furthermore, Server Components are not rendered to pure markup, but rather to a different format which allows for encoding of the client-side state within, and so that state isn’t “blown away” upon re-renders, even when it involves re-fetching the whole RSC component tree.
This doesn’t mean that you can’t use Server Components with traditional SSR though, both technologies are complementary and can work together.
These components can be either of a Server or a Client component; it then depends on the context, and what’s importing a Shared Component. A Shared Component imported by a Server Component will be rendered on the server as an RSC, while a Shared Component imported by a Client Component will be rendered on the client as a regular Client Component.
They will be excluded from the bundle as long as necessary, and requested on-demand if they’re ever needed in the client context due to some interaction.
It seems like Client Components are also downloaded dynamically only when necessary if they’re nested within an RSC that’s not part of the current route?
Suspense boundaries can be leveraged to define the UI behavior when waiting for the server to return rendered RSCs.
Even if the Server Components’ tree need to be re-rendered from the top down, the currently rendered UI can still be kept in place as-is while waiting for the missing/affected part to be sent down. This is due to the fact that RSCs do not render to HTML, but to a custom format that can be streamed from the server.
Is it that is “diffs” and keeps the locally-rendered unaffected Server Components in place, or is it that they simply arrived earlier on account of being higher up the tree and are displayed ASAP based on Supsense boundaries instead?
They are sent down as-soon-as-ready and displayed ASAP following Suspense boundaries. It doesn’t avoid the full from-the-app-root top-down rendering.
If you want to provide feedback immediately to the user before even waiting for the response, the useTransition() hook from React18 serves that purpose.
Thin wrappers for NodeJS standard APIs while providing functionalities such as caching. Like react-fs , react-fetch, etc. Some of those can be used in both Server and Client components.
Those will be implementable by the community. As of 05/2022, none of the ones leverages in the demos have been made public.
The server will only tell the client to download a Client Component’s definition if it is present in the RSC’s render tree. Nested Client Components are not part of the web bundle by default.
This currently depends on a bundler-level functionality exposed through a plugin. For the demo they used webpack, but this will eventually be developped further towards a production-ready version in collaboration with NextJS, and released publicly from there.
#qwik
$ here), and for developers to then adapt their mental models and leverage those synctatic elements and APIs.Need to setup boundaries and divide the code into subsets so that you don’t need to go from the root or have everything on hands to be able to hydrate parts.
Current frameworks use a main() function as the common, unique, entrypoint. To be truly progressive, a framework must be able to start hydration from multiple different entrypoints (Ideally defined boundaries, but at minimum top-level components as sub-roots or even child components).
Solving this requires cooperation from the framework’s runtime itself, as well as DSL-enabled syntax to define, at the implementation (author) level, said boundaries.
These boundaries eventually enable what is referred to as resumable hydration, where the framework can start exactly where it last left from, and not have to go back to the top and start top-down-from-root for a deep-nested child component.
The reason why most framework need top-down, from the root, hydration is to attach event listeners to the DOM nodes. That is knowing where to attach listeners, and what they should do/call.
The solution to this is to serialize the what and the where in the markup itself, so that hydration is essentially unnecessary - at least as far as it goes to rendering top-down to inferr what applies to who, and where.
The framework’s runtime can then implement a small global listener that knows where to listen for events and what to do with them, and asynchronously execute the related code by lazily fetching the listener’s implementation.
This is what enables true lazy loading - the framework emulates the bubbling of the events and then asynchronously executes the handlers, but this presents problems such as the fact that some events must be synchronous. Workarounds exists, but are highly complex.
Most current frameworks assume synchronous events, which then limits them in their ability to do true lazy loading. Async events execution is a requirement true progressive hydration.
The lazy-loaded event handles will often depend on the application’s state to process the user event, but lazy-loaded code has no idea about the current state of the application. Furthermore, in this new context there is no single entrypoint to build the state up from.
Much like with the event listeners, the solution is to serialize & deserialize the state to and from the markup in a consistent way, no matter which entrypoint initialized it.
Some frameworks can achieve that, but they assume that the state is a directed-acyclic-graph , which is rarely true. Furthermore, the state might contain [[#Non-Serializable Data Problem|items that can’t be serialized]] such as functions and Promises.
The framework needs to be selective with rendering - if it requires all of the code to be present to render a subset, then we’re no longer progressive - this is just delayed full hydration. So now, the plroblem is to figure out which components are invalidated as a result of state change.
Current frameworks solve this is one of two ways:
Both current approach result in eager download of rendering code! To achieve this properly, the framework needs to be able to track the data-component relationship through serialization of the relationships into the markup. That way the framework can asses the impacted components from a state change without having all of the code loaded and evaluated.
Qwik is a component-level reactive framework which serializes the relationships into the markup.
The solution, at this point, still cannot render components in isolation. An invalidated component still needs inputs to be (re)rendered, and those are provided by its parent.
There are two aspects to the above problem:
Assumed this is so the bundle doesn’t grow and we can keep component-level isolation without all descendants, which would invalidate the gain for higher-up components?
True progressive rendering means that the framework can both determine which components are invalidated as a result of state change - without the need for the component’s code - but also be able to re-render a component in isolation without forcing child or parent components to re-render as well.
One more responsibility of the framework is handling side-effects, usually through an Observer to Side-effect API, such as $watch() for Vue, useEffect() for React, or through “baked-in” mechanism such as Fields’ reactivity in LWC (which also offers extensions such as @track decorators).
A progressive hydration framework needs to be able to answer the following:
For the hydration to remain progressive, the framework must be able to do that only when needed. It needs to only download related code when the inputs do change. This requires taht the metadata about what to watch and what the current values are must be serializable to the DOM.
Not all data is serializable to the markup / DOM. The current frameworks don’t distinguish between serializable and non-serializable data types, but progressive frameworks must, and must provide the underlying APIs and mental models to allow developers to deal with this distrinction.
For instance, when a simple clock application is SSR’d and then resume on the client, it must re-register an interval so that the UI can update - the interval cannot be serialized and provided to the client as-is.
Non-serializable data includes Functions, Promises, Streams, and many more.
It is hard to satisfy all of the above constrains and still provide a good DX, especially one that would somewhat match the current zeitgeist in frontend frameworks. Today’s frameworks put DX first through the use of coarse abstractions and shortcuts that have brickwalled them outside of progressive hydration.
For progressive hydration to happen, we need a new set of frameworks that are built with it in mind from the ground-up, which is what Qwik presents.
#marko #quik
A new type of hydration, known as Resumable Progressive Hydration, could remove the need for any kind of hydration at all.
It requires, though, frameworks that are built with it in mind from the ground up, as well as a change in developers’ mental models.
Finally, the road to get to this is a complex one and poses multiple questions and problematic that needs to be addressed and solutionned - but the reward is the future of frontend frameworks; hydration that is entirely cost-free to clients and that allows both fast LCP and TTI.
Resumable Hydration basically comes down to not re-doing anything on the client that’s already been done on the server. Not re-running any components, nor executing any reactive expressions that already ran server-side.
This is enabled by avoiding the need for a reactive runtime (see Svelte and Solid) and by going to the smallest possible unit of change, ideally at an even lower level than a component. All of these “pieces” are then independently tree-shakeable and executable.
While effects are handy in that they are your opportunities to interract with the DOM, you usually want them to run after everything which means they require their own secondary queue. Furthermore, they can only run in the browser.
One possible solution would be to emulate a full DOM on the server side, through JSDOM for instance, so that effects could be applied as a last step to SSR, but it turns out that this yield abysmal performance as compared to string-based SSR.
But what’s relevant here is that, for frameworks that were built as such at least and that don’t rely on a full-blown runtime, basically only effects and event registration need to run on hydration. Furthermore, event registration can be a extremely light and simple process when the framework elevates the actual handlers to a global context, you only need to hook-up “notifiers”.
This means that if the end-user didn’t register any effects, nothing needs to be run beyond minimal code to bootstrap the global handlers.
Who’s the end-user here, the dev? Are we talking about declaring handlers that should run automatically, or taking actions client-side that’d cause effects to have to run post-Hydration?
See Marko’s
<effect>tag for context on Ryan’s perspective here. He’s here referring about effect having being “triggered” by user action client-side and waiting to be processed.Also, what is involved in bootstrapping the global handlers (assummed parsing and processing the provided JS) and are the “notifiers” simply inlined in the HTML and don’t need any further processing?
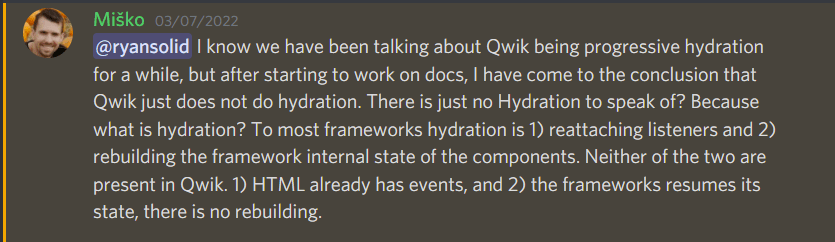
See below Misko Hevery saying that Qwik will include events in the HTML. Further details needed but this might simply be it.
With the above put together, it begs the question aout Hydration is then required at all; for instance here’s Misko Hevery saying that Qwik doesn’t need Hydration at all. Hydration is basically:
But in Qwik’s case, a framework tailored for this:
There is now a clear path to running exclusively browser-only code in the browser at hydration time, and nothing else. This is what resumability mean. Modern new-generation frameworks such as Qwik and Marko are built with this in mind, and some modern-er frameworks such as Svelte might have an easier time enabling that.
While this covers the execution of the code, the problem about serializing data remains; resumability even has the potential to make it worse. Various frameworks are working on and will land on different solutions - Marko for instance leveraging a reactive graph, along with the knowledge that the root of the page is only rendered on the server, to automatically detect what data needs to be serialized.
Important to note is also that resumability is independent from the strategy chosen on when and how the client-side code will be downloaded to the browser. This is significant in the fact that resumability is then complementary to many of the different strategies described above in previous articles.
#qwik
People tend to evaluate frameworks based on their syntax and DX, and end-up over-generalizing and missing the actually significant details. Ie. Solid == JSX == React…
SSR in current frameworks will give you great Time to First Paint, but terrible Time to Interactive, which can end up being multiple seconds on low power devices. This does a good job for SEO, but nothing for UX - which might in turn be negatively impacted through causing confusion or even losing or reverting actions and imputs.
Progressive Enhancement is a great way to address this delay, the time it takes the framwork to hydrate and become interactive, but you usually can still feel the wonkyness of the transition, and it might still negatively impact the UX if the delay is long enough that actions are taken in-between. Progressive Enhancement should serve as a resiliency technique for when JavaScript fails to load for some reason, but it isn’t a performance enhancement technique.
Qwik is resumable, while current frameworks are replayable. That is, Qwik only hydrates on the client what hasn’t yet been done on the server, while other frameworks will allow fully hydrating on the client too, but need to redo alot of what’s been accomplished by the server already. This requires Qwik to use a framework-specific serializtion format.
Misko uses Virtual Machines that can be suspended, moved, and resumed somewhere else, as a metaphor.
Progressive means “in parts”, not all happening at the same time or in the same whole.
To a lot of frameworks, progressive means simply to delay the hydration, but to Misko it is about splitting the code to the smallest possible unit, and to only ever bring what is necessary, at the moment it is necessary. You should not waste time downloading source that will not be executed, and you should start with the bare minimum that’s necessary to bootstrap the framework.
If I have a page, and most of the page is static, you shouldn’t have to download any code for the static parts, and you want a setup where user interactions will drive the download and execution of the code for items that are actually dynamic & interactive, in its minimal form, and only when needed.
Astro’s Islands are a much coarser-grained form of Progressive Hydration, in that they will only download source by chunks and will do it only when needed.
Where they differ though, is that Astro has replayable hydration at the Island-level. Islands are hydrated fully from the top down, where Qwik has replayable hydration.
Break Code into Chunks
The whole app isn’t being hydrated at once. You want only the code that’s necessary for a given interaction when it first occurs. To accomplish that, you need a way of breaking-up your application to the smallest-sized possible symbol. A component isn’t small enough, because a component is made up of many things (a template, handlers, effets, etc.) and all of these things are essentially closures that will run at some point in the future, but not now.
If you want to render a given component, you really (should) just need its template. And if you want to interact with a button, you need that button’s handler, but not all handler for all buttons…
There isn’t currently any standard tooling that allows for this kind of chunking. The closest is dynamic import statements, which isn’t quite as granular as we need it to be and has a heavy impact on the implementation - forcing file-based separation.
No Centralized Bootstrap
An app musn’t have a single entrypoint/starting point. Frameworks that rely on a “main()” method will require hydration to run top-down from the root. To achieve progressive hydration, each symbol must be its own independent and isolated entrypoint that can bootstrap the app by itself.
In turn, a centralized top-down bootstrap function will require much - often all - of the code ahead of time.
Serializing Event Handlers (into HTML)
When rendering the HTML on the server, you need to somehow be able to indicate that an interactive element has an event listener of some sort. You need to be able to serialize the what and the where; that is:
If you do not do that, as with current frameworks, you then need to leverage this single main() entrypoint which downloads and bootstraps the whole app from the top all the way down, executing each and every template, then figures out where the listeners should attach and apply, and finally assigns them to the provided rendered HTML. This is the exact opposite of what progressive hydration wants to accomplish.
To accomplish serializing the event hanlders into the HTML, Qwik injects a minimal bootstrap file on first render. It sets up a global listener on the document itself that intercepts user-events. It is that global listener that then knows, based on the inlined HTML listeners’ serialized information, which handler’s code to execute and, if need be, to first download it.
Unclear yet whether the global listener will go and “read” from the HTML-serialized information itself upon intercepting an event based on its source, or if said DOM event provides this information through reading its own attributes first.
Restoring the Application State
Once you know which handler’s source to download and execute, you need to restore the application’s state on which this handler depends. Handlers will often rely on application state or closed-over functions and values sourced from their lexical scope. A handler function alone isn’t much use, by itself is has “amnesia”, it was generated at build time without any of the current application state.
This complexity is increased tenfold by the fact that there is no single entrypoint from which the whole app state can be constructed. Each and every symbol is its own isolated entrypoint, and they each need to somehow be able to reconstruct the necessary app state, while taking over from where the server left off.
Invalidating State on Change
The handler function that gets called will most likely end up mutating the state - ie. an “Add to Cart” button. From there, the framework has to be able to figure out which components depended on that state and now have to re-render. That is, which components were invalidated as a result of that state change. This information also needs to be serialized to the HTML, since you cannot rebuild this information after the fact. The only way to obtain this information is to build the app.
Assumed this is serialized when compiling the app? Or is it that SSR will build & serialize information for every possible component, even those that are required on the first page (unlikely)?
Most current frameworks just figure that out by re-rendering everything from the root, which again is directly contrary to progressive hydration. Doing so requries the complete source of the app, and means re-doing work that’s not only already been done by the server before, but also potentially by the client.
Out of Order Rendering
Once you know which components need re-rendering, how do you render them in isolation, without re-rendering the parent(s) nor the children(s) as well. This is a complex issue since a given component receives props from its parent, and can also provide props for its children(s), if not the childrens themselves.
None of the current frameworks can do this from the SSR. Some, like Svelte, can re-render components in isolation but only after the app has first fully hydrated from the root down, which requires the full app code.
Can Svelte re-render components in complete isolation, or is it more like a single, complete of parents and childrens, branch of the render tree?
Observing Side Effects
After rendering out of order (in isolation), you need to be able to tell which reactive property/functions, enabled through various framework APIs, should run.
Misko compares those reactive items to headless components, in that they have those inputs/props and then, upon change, have parts that need to run - albeit not a rendering function in that case.
Idealizing Bundles
After having broken everything down to their smallest-possible units, you still want to create bundle that provide related, cohesive, and often related, items together. Getting everything on-demand on its own isn’t a goal as that would in itself hinder performance significantly.
The way that Qwik aims at determining these bundles is through analtics. By tracking user’s behavior though actual usage, you can eventually correctly produce the most optimized chunks based on actual utilization data.
Once the chunks have been organized, you can use this same data to determine the order in which those chunks should be required, as well as the points & interactions that should drive the likelyness of requiring another chunk in the future. From there, you can start pre-fetching those chunks on the client.
Developer Experience
You cannot shoehorn Progressive Hydration in an existing framework without incurring significant costs in terms of breaking changes and added complexity. It needs to come from the ground up in terms of primitives and mental models.
Qwik went through many iterations of its DSL, some of which were wildly out there and were an active repellant to its adoption, but have now stuck a balance that makes it flow through familiar syntax and approchable concepts; granted it still takes adjustment from the developers in terms of how they think their code through.
$ SuffixThe $ suffix is an optimiser instruction. It essentially means that a symbol boundary should be placed there. Whatever is being defined, or returned in case of an expression, should be placed into its own symbol - its own file.
useStyles in this case, it means that the product of the hook running should be made into its own symbol/file.For instance, the following transformation occurs behind the scene:
useStyles$(globalCss);will become the following custom dynamic import statement for a generated chunk, under a given symbol identifier:
useStyles(qrl('./q-b2342.js', 'App_Styles'));The challenge with this sort of separation is when it comes to closures. Extacting will change the lexical scope and closed-over variables are lost. The framework must be able to reconstruct it.
The $ also means that certain things that are valid JavaScript aren’t allowed; it is an indication to the developer that he has to think in terms of those restrictions - much like hooks in React aren’t just allowed everywhere.
useLexicalScope()When closures are detected by the framework, the useLexicalScope() is injected in the symbol’s definition, which has its closed-over variables serialized in its qrl locator.
The framework then serializes all of the closed-over variables themselves to JSON and assigns each one a unique identifier. It then inlines that JSON to the rendered HTML as a script tag.
Any reference anywhere in the codebase to one of the closed-over variable will instead be replaced with a q:obj="..." reference to that unique identifier.
The very first function that gets called that includes useLexicalScope() will then parse & consumme that JSON script and inject the corresponding values associated with the various identifiers in all registered consumers - determined by the q:obj="..." attribute on DOM elements - essentially lazy-loading closures.
Qwik is a reactive framework, and uses JS proxies to handle the observability aspect; tracking changes and invalidating dependent components as a result.
From a component’s internal perspective, it acts like it has a virtual DOM; but is reactive through proxies when it comes to cross-components interactions.
Ryan mentions that the closest current framework in terms of the way it operates is Vue. Assumed this is a reference to how
watchersandcomputed propertiesare implemented internally, but more information needed here.
Since all the data is stored on the DOM, the proxies here allow for transparantly syncing the properties of an element to its attributes.
Assumed that the opposite direction is also true? What if a reference is held in memory, will it also be updated live? Upon next access?
Misko saying that “the DOM is the source of truth” and that “we can’t keep the data with us” leads to belive that any proper access is always read back from the DOM …
! in q:obj="..."Within a q:obj="" attribute are listed a given element’s dependencies and subscription. Within that list, items’ identifiers preceded by a ! denotes items to which the element is subscribed, and for which, upon change, the element should be invalidated and re-rendered.
The absence of the ! denotes a simple reference. The element shouldn’t be re-rendered when a given item changes, but it should if it gets re-assigned completely.
Build time reactivity imposes the constraint that you can’t include any type of conditionals. The reactive parts will run every time, unconditionally.
The alternative, runtime reactivity, is more flexible but comes with the constraint that it has to be ran fully at least once, to identify the dependencies. Qwik has an interesting approach to runtime reactivity that avoids putting the load of this initial run on the client; with everything else that this implies.
In Qwik’s case, the server rendering will “snapshot” the dependencies at build time and serialize them into the HTML all over the application.
Then, similarly to reactive programming, the elements themselves - through their proxies consuming their attributes - will manage their subscribers list and will thus notify & invalidate them automatically on change with full knowledge of who they are.
The framework essentially makes everything reactive, since the dependencies are fully captured, but for pieces that simply cannot be modified by the current implementation, they’ll never have to change and thus no additional source is wasted handling those. Should we artificially change some of those - with the dev tools for instance - the app will correctly react just the same.
This is in opposition to a VDOM-based framework where components need to be re-rendered in memory and then diffed against their current version to figure out if they should be repainted (or “committed”) every time - or explicit opt-out mechanism need to be setup, such as memoization.
Content projection is the act of passing content/components to a parent component for it to render within itself. It is a delcarative alernative to using a children prop, which is common in the vDOM-based frameworks.
Using projection, through the concept of Slots, Qwik is able to fully isolate each components on their own and thus can respect their rules of being able to re-render a parent without having to re-render its contents, and inversely.
Slots allow components to define explicitly the source of a projection, and its destination. This sets up a boundary where the child can then change what is projected, and the parent can change how, without having to depend on the other.
In the case of children props, a parent component can imperatively modify the children any way it wants and thus the rendering of both parent and childrens is necessary.
It can also be seen as the children prop model doing lazy evaluation of childrens provided, where Slot, at least in Qwik’s case, are eagerly evaluated. Web Components, with the Shadow DOM, also work that way and eagerly evaluate children in the sense that they will always put the children in.
Ryan mentions that even other current frameworks which rely on Slots have moved over to lazily evaluating them (Svelte, Vue, Solid). He says that none of the modern SPA frameworks eagerly evaluates childrens, and that chaging this would be completely breaking. He mentions that this is so if you do conditionals, you don’t have to do any extra work. You can use childrens as a sort of “control flow” … More info/specifics needed on this.
This, in turn, means that Qwik doesn’t support renderProps, in the sense that JSX cannot be passed around as props to a component.
Qwik uses the onWatch$(...) function - its React’s useEffect(...) equivalent - and the q:watch="..." attribute to track side effects relationships.
This attribute specifies the associated file/bundle and symbol that should be executed, as well as the conditions. I.e. “Only run this function if these objects got modified”, where the objects’ identifier are listed between | pipes within q:watch="...". The attribute lives on the dependants.
Chunking is provided by a Vite plugin and can be cusomized manually.
The bundler determines how chunks are organized and the framework when they’re being downloaded based on usage data.
The framework can do off-thread worker download of further chunks.
#qwik
Qwik is the first-of-its-kind, truly Resumable framework, which breaks chunks to units smaller than the components themselves, and doesn’t require true hydration once on the client side.
Instead it serializes all of its data and metadata in the rendered HTML and then lazy loads the JavaScript on a need-to basis, and through usage-data-driven optimized chunks.
Hydration is overhead because it duplicates the work that’s already been done on the server, as part of SSR/SSG, on the client. It forces the client to eagerly download and execute the application’s code to rebuilt the what, where, application’s state, and framework’s state on the client for it to be able to tell which event handler should apply to what DOM element and event type.
Resumability codifies the work of the server in the rendered HTML, so that the client can pick up where the server left off, without any duplication of the work. Furthermore, resumability creates and loads the events handler lazily, and releases them after their execution, in turn meaning that no useless work is frontloaded to the app’s initialization, and that the memory footprint at runtime is minimal.
Overhead should only include whatever is done twice or can be avoided. Most of the definitions of Hydration include in its cost the process of attaching DOM Events Listeners to the rendered HTML, but realistically this process is both lightweight and necessary regardless.
The truly expensive, and unnecessary, part of Hydration is the need to “replay”, or fully rerender, the whole application from the top to be able to proceed with an interactive frontend.
Knowing what event handlers are required where is the hard part of hydration. To further define those terms:
Basically, hydration is a method of recovering the above, by download all of the code eagerly and by executing it on the client so that the whats and the wheres can be determined. That, consequently, happens to be the expensive part. The steps can be broken down as such:
The recovery phase is a name given to the first 3 steps described above. It consists in trying to rebuild the application, which in turn requires downloading and executing the app’s code.
It is an expensive phase that scales directly with the size of the underlying app, and directly affects the “startup” time of web apps.
In the context of hydration, this phase qualifies as pure overhead, as it essentially consists in re-doing work that’s already been done on the server as part of the SSR/SSG. The site is sent to the client twice, once as HTML, and again as JavaScript.
The way to avoid having to redo all that work is to serialize the information as part of what’s provided to the client, so that it can start where the server left off.
To avoid the overhead, a framework must avoid all of the 4 steps listed above. It instead needs to:
The key component here is the factory function, which allows creating the whats lazily as a response to a user event, instead of eagerly as required by hydration to enable interactivity.
A good way to oppose hydration and resumability is as follows:
Here’s a snippet of code that displays how Qwik goes about serializing, the what, where, application’s state, and framework state, as part of the SSR’d HTML.
<div q:host>
<div q:host>
<button on:click="./chunk-a.js#greet">Greet</button>
</div>
<div q:host>
<button q:obj="1" on:click="./chunk-b.js#count[0]">10</button>
</div>
</div>
<script>/* code that sets up global listeners - executed immediately */</script>
<script type="text/qwik">/* JSON representing APP_STATE, FRAMEWORK_STATE */</script>The HTML element’s attributes encode the where. When an event occurs, the framework lazily deserializes the application and framework state to complete the what and execute it.

Resumabilty has the advantage, over hydration, that handlers are created and allocated on-demand, and then immediately removed after execution. This means that the memory footprint of an application is minimal, and that handler’s repeat execution performance is linear.
How does this constant re-creation of handlers affect runtime performance for often utilized handlers?
In the case of hydration, all handlers are created eagerly and kept in memory for the lifetime of the application.
None of the existing terms around hydration would properly describe what Resumability does. “Hydrated after the global even handler is registered” is misleading, since no app code has to be downloaded even then, and “Hydrated when the first interaction parses the serialized state” is also reductive, since even then there isn’t any complete hydration of all handlers.
It can be seen, as per Ryan Carniato, as a step-up from Progressive Hydration, known as Resumable Progressive Hydration.
Furthermore, there are situations where event can be handled without having to even deserialize any state, and when the state is first deserialized, it is for every components - even those that might not have been downloaded yet, and without the need to download them to do so. In that, Qwik thinks of this as lazy app state deserialization, instead of in any terms that would qualify the concept of hydration as a whole.
That’s one way to look at it, althout here again hydration suggests that it would need to download and execute related component’s code, where Resumability allows for code execution without any of this, in complete isolation, based on the serialized information:
It’s much faster and consistently reaches 100/100 pagespeed scores, where older Hydration-based versions would reach around 50/100.
Reference
No, because Prograssive and Lazy hydration still cannot continue where the server’s left off - they have to re-do the work on the client to achieve interactivity, and to do so they need to eagerly download all of the components code and evaluate it.
With Resumabilty, much of that code might never even get downloaded but interaction is still possible, and its still possible to author the components in such a way that they pass props to child components or project content in childrens.
Recovering props is also the reason why even strategies that “chunks” the interactive parts from each other, such as islands architecture, cannot be arbitrarily small.
No, Islands can break down the work into smaller chunks and can make it so that alot less needs to be frontloaded to the initialization of the app, but it still is hydration when you look at the islands themselves.
The word state here can mean many things, but it tends to referr to the application’s state.
Even though serializing the app’s state is a significant improvement, it still doesn’t avoid the need for hydration, since the what, the where, and the framework’s state are all required to be serialized if you want to avoid the need for hydration.
There is no difference between the first time a handler runs, and subsequent times.
The main point of difference is whether or not the state has been deserialized, which occurs on the first interaction.
Not if you use prefetching. Qwik is unopinated on prefetching, but finds that it should be leveraged to obtain the best experience, especially if left off-thread to a Web Worker (suggested through Partytown).
Qwik is looking into ways to enable interop with with other framewoek’s components, where Qwik would act as an orchestrator.
This is a work in progress.
import ReactButton from '@mui/material/Button';
import { qwikify$ } from '@builder.io/qwik/react';
const Button = qwikify$(ReactButton);
// Coming soon!
export const MyQwikComponent = component$(() => {
return <Button>Hello world!</Button>
})Table built from content of this article only - not reflective of the full and/or current landscape and state ↩
All credit for the source and/or referenced material goes to the named author(s).